
很多搜索软件和网络搜索服务都声称它们易于非程序员使用,而它们真正想做的是吸引非程序员市场。
有些网络搜刮服务会让任何人感到困惑,无论其编程能力如何。我将稍微详细地解释一下他们所说的 "易用 "是什么意思。
不同类型网络刮刀概述
- Octoparse:带云服务的最佳网络搜刮软件
- Import.io:最好的基于网络的商业刮板
- ParseHub - 可视化网络搜刮软件
- Web Scraper:用于网络搜索的 #1 Chrome 浏览器扩展
- BeautifulSoup:用于 DIY scraper 的开源 Python 库
- ZenRow:最佳网络搜索 API
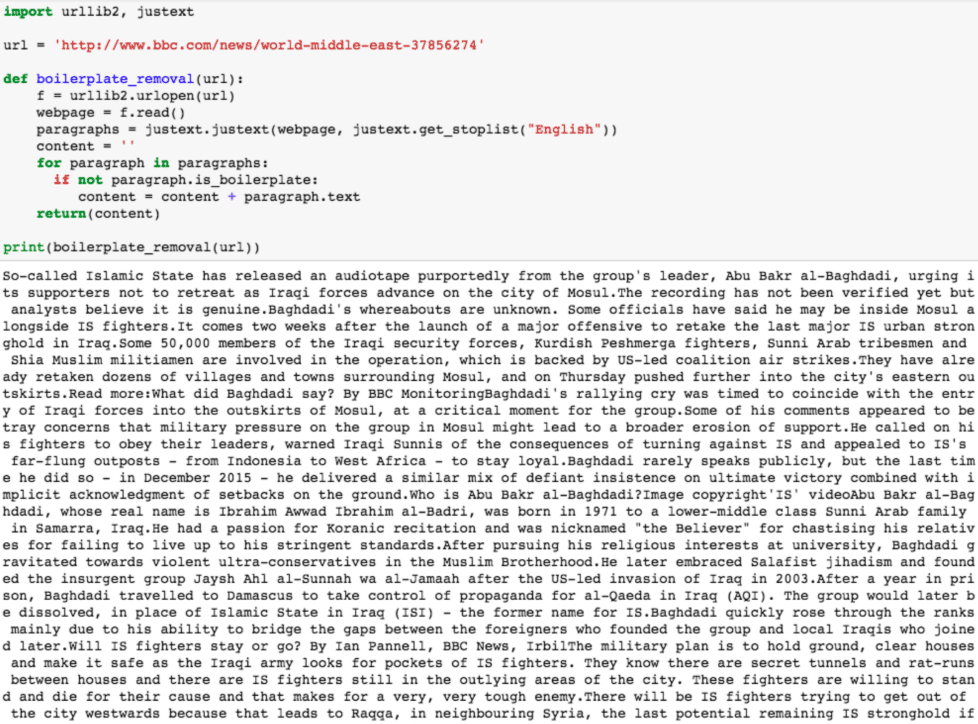
关于网络搜刮,有一点需要牢记,那就是自互联网诞生以来,人们就一直在进行网络搜刮。在 Wayback Machine它试图记录(即抓取)在已知的万维网网络中出现过的每一个网页。下面是一个使用 Python 2 的 Python 脚本(运行正常)的例子,它能完美地抓取网页。我亲自运行了它,现在它可能已经过时半年了。
这意味着,进行网络搜索的方法并没有错。你所选择的方法总是有利有弊,但只要你能得到你想要的结果,你就达到了目的。有时,消费者会认为他们可以找到比现有方法更好的方法,试图用新的方法取代旧的方法,认为新的方法总是比旧的方法更有吸引力。 网络搜刮软件 或软件包。情况并非总是如此。下面这些评论将试图找出哪些服务真正脱颖而出,哪些只是平庸之辈。
10 款用于数据提取的最佳网络搜刮工具和软件
1. Octoparse
适用于 Windows 的最佳桌面网络搜索应用程序,适用于 Mac 的虚拟机
Octoparse 因其丰富的功能集而被誉为网络搜刮服务之王,但在很多方面,这些功能似乎都会造成堵塞,让人不清楚如何做一些简单的事情,这可能会让人苦恼。甚至当一个项目发展到更大的规模时,整合每一个小构件都需要大量乏味、不直观的界面,这些界面迫使你以某种方式进行设置,而这些设置日后可能会不兼容。
除此之外,Octoparse 还具有丰富的功能和实用性;它可以建立网页搜刮协议的可视化路径,包括从每个网页搜刮的具体内容、 如何旋转代理是否循环函数,以及是否调用 API。然后部署提取协议,看它施展魔法。

如果一切按计划进行,搜刮到的数据应能清晰地显示在表格中,并可导出为所选的表格文件格式。总的来说,这是一项出色的网络搜刮服务,也可能是目前最实用的网络搜刮工具。
虽然价格偏高,但对于没有编码经验的小型和大型操作来说,还是值得的,因为在这种情况下,如此复杂的工具是保证正确完成网络搜索的最佳方式。
2. Import.io
最适合企业的网络搜索服务

如果你需要一些简单的东西,Import.io 是最容易使用的网络搜刮服务之一。注册后,它就可以开始工作,要求你输入要下载信息的 URL。
与同时向用户灌输所有功能和可能性的软件平台或仪表盘相比,这可能更可取。Import.io 保持简单,这可能是一件非常好的事情。这也是实现易用性的一种方法。
3. ProWebScraper
无代码网页抓取工具
我们喜欢的另一款工具是 ProWebScraper,它是一款功能强大的基于云计算的工具。 刮刀.ProWebScraper 可让您从几乎所有地方搜刮数据,包括 js 渲染的网站和 HTML 表格。它们采用旋转 IP 机制,可防止 IP 屏蔽。
更重要的是,他们保持了工具的易用性,大多数情况下只需点击即可。虽然他们是一个相对较新的工具,但很快就变得流行起来。越来越受欢迎的背后有两个原因,一是他们的免费刮板设置服务,二是他们的定价。他们提供的 1,000 个免费页面点数也相当慷慨。
4. Mozenda
云托管搜索软件和数据采集服务

Mozenda 是一款可靠的高端网络搜索服务。它深受合法企业的信赖,而且据许多产品用户称,它能完成任务。用户也抱怨学习曲线比较陡峭:一开始,很难指示 Mozenda 准确地从网页上搜刮用户希望它搜刮的内容。
不过,一旦克服了学习曲线,它似乎是一种可靠的方法,可以从不须 API 或包含其他限制的网站上刮取数据。请随时查看其"/robots.txt "页面,了解更多信息。
5. ParseHub
可视化网络抓取软件

与竞争对手相比,ParseHub 有一些明显的优势。作为软件,它兼容所有三大操作系统:Windows(从 7 到 10)、Mac(从 OS X El Capitan 开始)和 Linux(Debian,与最新的 Ubuntu 兼容)。 可通过命令提示符使用以下命令进行设置(按操作系统顺序):
Parsehub 可能是这份清单中我最喜欢的一款。它的仪表盘只是一个网页--它的易用性在于它的简单性,同时也提供了大量的灵活性。你可以手动抓取几个页面,也可以给它指令让它自动抓取。这就是我喜欢它的原因之一,因为它的概念。
6. Dexi.io
这篇文章对随机行走的数据抓取器进行了可视化,但并没有真正为我提供任何信息--只是一个看起来很酷的图表,显示了它的网络抓取器计划抓取的内容、计划抓取的方式以及它将从每个页面抓取的内容。
换句话说,它向你显示的正是你刚刚给它下达的指令。也许这对某些人来说是个令人愉悦的功能,但这似乎并不能成为选择它而不是其他产品的理由(虽然它并不是唯一一个提供仪表盘的产品,但它提供的仪表盘并没有太多的地狱功能)。
7. Diffbot
Diffbot 看起来非常有前途,特别是如果它声称与之签订合同的供应商都是合法的(eBay 是最大的,但也有很多其他供应商),我们没有理由不相信他们。
疤痕平台还附带了一些额外的功能,但不会影响整个系统的用户体验。
知识图谱似乎决定了被搜刮数据的类型。在自然语言处理中,这种机器学习技术被称为命名实体识别。在命名实体识别中,根据训练有素的模型对文本进行解析、清理和总结,以预测短语、句子、单词甚至整个文档的主语或宾语。
Diffbot 似乎也加入了这一功能,不过大多数网络刮擦工具本身可能对其刮擦的网站以及这些网站的内容有所了解。因此,这可能会非常有用,也可能不会非常有用,但这并不意味着整个软件包乏善可陈。
8. Web Scraper
用于提取网络数据的 Chrome 浏览器扩展
这是最简单的网络抓取工具。尽管如此,它还是提供了一些有用的工具,能直截了当地抓取网页上的所有内容,并循环抓取预先指定的网站列表。
它还可以根据需要或时间轮换代理服务器;对于后者,过剩的代理服务器可以使其有效工作,因为 IP 会在与目标网站发生协议问题之前被切换掉。
当然,将整个网络搜索工具作为一个附加组件下载,而且该附加组件实际上是一个相当称职的网络搜索工具,这种简便性也是值得一提的。
9. Agenty
Agenty 有别于其他网络搜刮服务,因为它不仅能搜刮文本或整个网页,还能搜刮网页中的任何嵌入式多媒体内容。除此以外,它的一些技术功能(如基于 REST 的应用程序接口功能)给一般的网络搜刮任务带来了更多的困惑,而不是清晰度。
其他领先的网络搜刮工具都不包括这一点,因为没有必要,就像没有必要像 Agenty 那样将提取的数据存储在云端一样。不过,它的试用期很宽松,可以试一试,在 100 个网页上试用一下,看看是否适合任务的需要。
10. ScrapeHero
有关 ScrapeHero 的评论以及使其与众不同的是客户服务。众所周知,Scrapehero 能在几分钟内回复任何问题,客户服务代表可以在一天中的任何时间帮助客户解决任何问题、困难、需求或疑虑。
它的定价比同类网络搜刮工具要高,但对某些人来说,这种额外的响应速度值得付出额外的成本。作为一个平台,它所包含的功能不如 Octoparse 但它仍能提供一种有效的方法,通过 HTTPS 协议从网站和旋转代理中获取数据。这是一个可靠、易学的平台,对于企业来说可能是最经济实惠的,但仍值得大量使用。
11. BeautifulSoup/Selenium/DIY
有时,使用编程脚本是获得可靠的网络搜刮源 3ef 的最佳方法,您可以一次又一次地返回到该网络搜刮源。
如果有可能,这可能是最好的解决方案。其明显优势在于可靠性。软件会出错、崩溃、更新或停止接收更新。有了 Python,您就再也不用担心这些问题了。 Python 软件包 随处可见:美丽的汤 硒Curl、urllib(3 或 2,取决于 Python)等等。
仅这些就能为您提供所需的最佳网络爬虫,它可以在代理之间循环,避免 Selenium 的检测。此外,在 Python 中,数据的存储、清理、格式化和导出可以变得天衣无缝,或者至少能够将数据转换为正确的类型,然后导出为 JSON 或 CSV 文件,而无需额外的麻烦。当然,前提是刮擦器的编写要清晰、高效,以避免编程错误。
在这两款软件中,我最喜欢的两款(除了自己编写网络爬虫程序之外)是 Parsehub 和 Import.io。Import.io功能丰富,同时又保持了简洁性,而简洁性正是你所需要的。
硒 将在后面进一步讨论,因为它是一种相对独特的网络刮擦工具,可以通过 python 以外的其他方式加以利用。
12.ZenRows
最佳网络搜索 API
ZenRows 是开发人员从网站中提取数据的最可靠解决方案,可减少路障、不确定性和基础设施成本。
该工具包可为您提供优质的 代理旋转器这些功能包括无头浏览功能、高级反僵尸绕过功能以及任何大规模项目都需要的其他功能。
ZenRows 可与 Python、PHP、Ruby on Rails 及其他编程语言无缝集成。此外,它还拥有由自己的开发人员提供的世界级支持。
常见问题
使用开源网络搜刮工具有哪些利弊
开源网络搜索工具各有利弊。使用开源工具的主要优点是可以免费使用,而且可以根据用户的需求进行定制。这些工具还拥有一个庞大的开发者社区,他们为工具的开发做出贡献并提供支持。不过,开源工具的支持和文档水平可能不如商业工具。它们的功能也可能有限,可能不适合复杂的网络搜索任务。此外,开源工具可能不像商业工具那样用户友好,需要更多的技术知识才能有效使用。总之,选择使用开源还是商业网络搜刮工具取决于用户的具体需求和资源。
哪些是最流行的开源网络搜刮工具
一些最流行的开源网络搜刮工具包括 Scrapy、Heritrix、Web-Harvest、MechanicalSoup、Apify SDK、Apache Nutch、Jaunt、Node 和 Octoparse。这些工具具有多种功能,如易于使用、支持多种编程语言以及能够从复杂的网站中提取数据。Scrapy 是最流行的开源网络搜刮工具之一,而 Octoparse 则是一款免费且功能强大、特性全面的网络搜刮工具。不过,最佳工具的选择取决于用户的具体需求,如需要提取的数据类型、网站的复杂程度和预算。
从动态网站提取数据的最佳网络搜刮工具有哪些?
Python 和 Selenium 是网络动态网站刮擦的常用工具。Python 库(如 BeautifulSoup 和 Scrapy)可用于解析 HTML 并从动态网站中提取数据。Selenium 是一种浏览器自动化工具,可以模拟用户与网站的交互,从而实现动态内容的搜刮。Octoparse 和 Apify 等其他工具也提供了用于动态网站搜刮的功能。Octoparse 可模拟人工刮擦过程,使整个刮擦过程简单高效。最佳工具的选择取决于用户的具体需求,如网站的复杂程度、需要提取的数据类型以及预算。
使用 Python 进行网络搜索有哪些优势?
Python 因其简单、易读和易用而成为网络刮擦的流行语言。Python 有大量的库和框架,如 BeautifulSoup、Scrapy 和 Selenium,可以让网络刮擦变得更容易。这些库提供了 HTML 解析、浏览器自动化和数据提取等功能。Python 的动态键入和高级内置函数也使编写复杂命令变得更容易,只需更少的代码行,从而使网络搜索更高效、更省时。此外,Python 还是一种理想的自动化语言,非常适合需要导航到网站、登录和提取数据的网络搜索任务。总之,Python 的简洁性、可读性和自动化功能使其成为网络搜索的热门选择。
有哪些最流行的 Python 库可用于网络刮擦
一些最流行的用于网络刮擦的 Python 库包括 Beautiful Soup、Requests、Scrapy、Selenium、lxml 和 Playwright。Beautiful Soup 是一个流行的库,用于从 HTML 和 XML 文档中提取数据,而 Requests 则用于发出 HTTP 请求和处理响应。Scrapy 是一个强大的 Python 框架,用于从网站中抓取和提取数据,而 Selenium 则是一个浏览器自动化工具,用于刮擦动态网站。Lxml 是一个快速且功能丰富的库,用于解析 XML 和 HTML 文档,而 Playwright 则是一个相对较新的库,为浏览器自动化提供了一个高级 API。最佳库的选择取决于用户的具体需求,如网站的复杂性、要提取的数据类型和预算。
总的来说,尽管上述两个程序是我的最爱,但我还是倾向于确保脚本能够运行。当然,在很多情况下,代理服务会让生活变得简单很多很多,但有时它们本身也会让人头疼。
