
A lot of scraping software and web scraping services claim that they are easy to use for non-programmers when what they’re really trying to do is appeal that market.
Some web scraping services are confusing to anyone regardless of their programming capabilities. I’ll explain in slightly greater detail what they mean by easy to use.
Overview of different type of web scraper
- Octoparse: Best web scraping software with cloud services
- Import.io: Best Web-based scraper for business
- ParseHub – Visual web scraping software
- Web Scraper: #1 Chrome Extension for web scraping
- BeautifulSoup: Open-source Python library for DIY scraper
- ZenRow: Best web scraping API
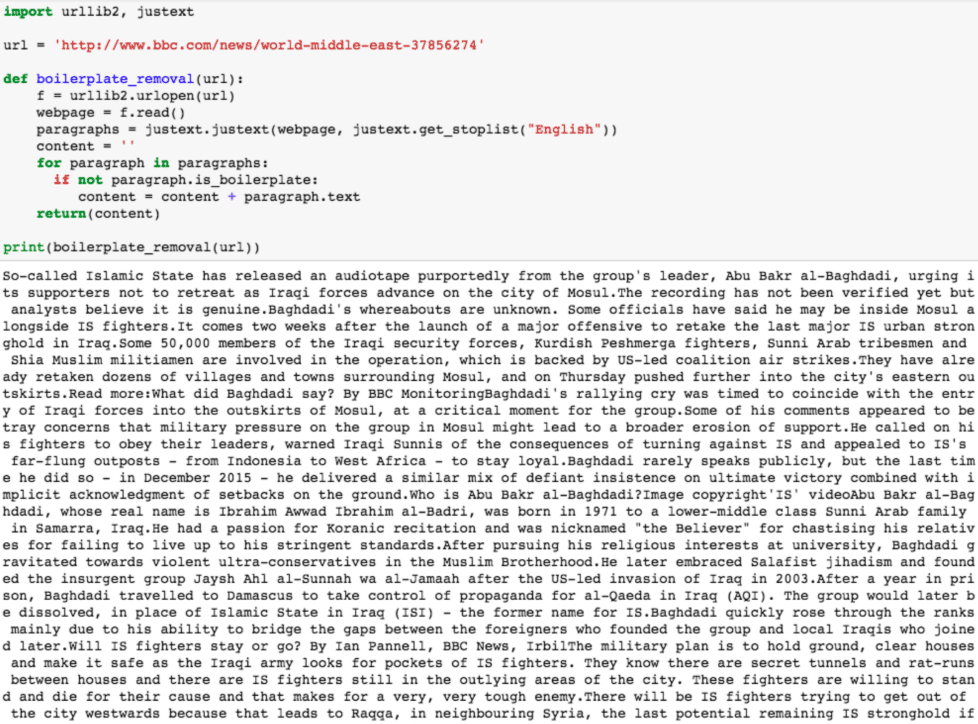
One thing to keep in mind about web scraping is that its been something that’s been done since the start of the internet. There’s evidence of this in the Wayback Machine, which attempts to chronicle (i.e. scrape) every webpage that has ever seen the known network of the world wide web. Here’s an example of a (WORKING) Python script using Python 2, crawling webpages perfectly. I ran it myself, and it probably has been outdated for half a decade by now.
What this means is simply that there’s no wrong way to do web scraping. There are always pros and cons to the methods that you choose, but as long as you get the results you’re going for, you’ve achieved your goal. Sometimes consumers think they can find something better than what already works, trying to replace the wheel, thinking the grass is always greener with some shinier newer web scraping software or package. This may not always be the case. These reviews below will attempt to identify which services truly stand out from the pack, and which ones are just mediocre.
10 Best web scraping tools & Softwares for Data Extraction
1. Octoparse
Best Desktop web scraping app for Windows, Virtual machine for Mac
Octoparse has been lauded as the king of web scraping services because of its expansive set of features, but in many ways, those features seem to clog and make it unclear how to do simple things, which can be aggravating. Even when a project is developing into something larger, incorporating each little building block requires a lot of tedious, unintuitive interfaces that force you to set things a certain way, which may later be incompatible.
Beyond that, Octoparse is loaded with features and usability; build a visualization of the path that the web scraping protocol will take, including specifications of what exactly it will scrape from each webpage, how to rotate proxies, whether or not to loop functions, and whether or not to invoke APIs. Then deploy the extraction protocol and watch it work its magic.

If all goes as according to plan, the scraped data should be cleanly displayed into a table and ready to be exported into the tabular file format of choice. An overall excellent web scraping service, and possibly the most useful tool out there for web scraping.
While on the pricier side, it’s worth it for smaller and larger operations for those without coding experience, because in that case, tools this sophisticated are the best way to guarantee that the web scraping is being done correctly.
2. Import.io
Best web scraping services for business

Import.io is one of the easiest web scraping services to use if you need something simple. As you as you sign up, it’s ready to go, asking you to type in the URL you want to download information from.
This can be preferable when compared to software platforms or dashboards that bombard the user with all of the features and possibilities at once. Import.io keeps it simple, which can be a very good thing. This is one way of achieving ease-of-use.
3. ProWebScraper
No code Web Scraping Tool
Another tool we’ve come to like is ProWebScraper, a powerful cloud-based scraping tool. ProWebScraper lets you scrape data from pretty much everywhere, including js-rendered websites and HTML tables. They work on a rotating IP mechanism that prevents IP blocking.
What’s more, they’ve kept the tool easy-to-use; mostly it’s just pointed and clicks. Though they are a relatively new tool, they’re quickly becoming popular. The two reasons behind this growing popularity are their free scraper setup service and their pricing. And their offer of 1,000 free page credits is pretty generous too.
4. Mozenda
Cloud-Hosted Scraping software & data harvesting services

Mozenda is a reliable, high-end web scraping service. It’s trusted by legitimate businesses and according to many users of the product, accomplishes its tasks. Users also complain about a rather steep learning curve: at first, it is difficult to instruct Mozenda to scrape exactly what the user wants it to scrape from a webpage.
However, once that learning curve is overcome, it appears to be a reliable method of scraping data off of websites that do not require an API or contain other restrictions. Always check their ‘/robots.txt’ page for more information.
5. ParseHub
Visual Web Scraping Software

ParseHub has a few distinct edges over its competitions. As software, it boasts compatibility with all three major operating systems: Windows ( from 7 to 10), Mac (from OS X El Capitan onwards), and Linux(in Debian, which is compatible with the latest Ubuntu). It can be set up from the command prompt with the following commands, in order (per operating system):
Parsehub is maybe my favorite one on this list. Its dashboard is just a webpage – it’s ease of use lies in its simplicity it also offers a ton of flexibility. You can crawl just a few pages by hand or give it instructions to perform take automatically. That’s one of the things I like about this is that its concept.
6. Dexi.io
This one had visualizations of the random walking data scrapers that didn’t really provide me with any information – just a cool looking graph that shows what it’s web crawler plans to crawl, how it plans to do it and what it will scale from each page.
In other words, it’s showing you exactly the instructions you’ve just given it. Maybe that’s a pleasant feature to some but it doesn’t seem like a reason to choose it over others (although it’s not the only one guilty of providing dashboards that don’t hell with much.
7. Diffbot
Diffbot looks incredibly promising, especially if the vendors it claims to have contracts with are legit(eBay being the biggest names, but many others as well) and there’s no reason not to believe them.
The scarping platform comes with extra perks that don’t override the entire user experience of the system.
The knowledge graph seems to determine the type of data being scraped. In natural language processing, this machine learning technique is called named entity recognition. In named entity recognition, the text is parsed, cleaned and summarized based on trained models in order to predict the subject or object of a phrase, sentence, word, or even entire document
Diffbot seems to throw this in, although most of the web scrapers themselves probably have an idea of the websites their scraping, and thus, the content of those sites. Therefore, this may or may not be extremely useful, but that doesn’t mean the whole package is lackluster.
8. Web Scraper
A Chrome Extension for web data extraction
This is the simplest form of web scraping tools available. Despite this, it does provide some useful tools alongside its ability to bluntly capture everything on a webpage and cycle through a pre-instructed list of sites to crawl.
It can also rotate proxies as needed or based on time; with the latter, a surplus of proxies can allow this to work effectively because the IPs will be switched out before they run themselves into protocol issues with the targeted website.
There’s also, of course, something to be said for the simplicity of downloading an entire web scraping tool as an add-on, with said add-on actually being a fairly competent tool for web scraping.
9. Agenty
Agenty sets itself apart from other web scraping services because it excels in scraping not only text or entire webpages but any embedded multimedia content within the webpage as well. Other than that, some of its technical features add more confusion to the average web scraping task than clarity, such as its REST-based API feature.
This is not included in other leading web scraping tools because it is unnecessary, just as it is unnecessary to store the extracted data in the cloud, as Agenty does. Its trial is generous enough to give it a shot however, try it on 100 web pages and see if it suits the needs of the task.
10. ScrapeHero
The reviews regarding ScrapeHero and what sets it apart has been the customer service. Known to reply to any concern within minutes, Scrapehero has customer service representatives available at any time of the day to help their customers with any questions, problems, needs or concerns.
Their pricing is steeper than comparable web scraping tools but for some, this extra responsiveness is worth the extra cost. As a platform, it does not contain as many features as Octoparse but it still provides an effective method of scraping data from sites and rotating proxy via HTTPS protocol. A solid and easy-to-learn platform that may be most affordable for businesses, but worth taking a lot at nonetheless.
11. BeautifulSoup/Selenium/DIY
Sometimes the best way to have a reliable source 3efor web scraping that you’re able to return to time and time again is achieved with the use of programming scripts.
If this is a possibility, this may be the best solution. The distinct advantage is reliability. Software messes up, crashes, updates, or stops receiving updates. You’d never have to worry about that with Python accompanied by Python packages used everywhere: Beautiful Soup, Selenium, Curl, urllib(3 or 2 depending on the Python), to name a few.
Those alone can get you the best web crawler you need, one that cycles between proxies, avoids detection in Selenium. Also, storing, cleaning, formatting and exporting the data can become a seamless process in Python, or at least the ability to transform the data into the correct type and then export it to a JSON or CSV file without any additional headaches. This, of course, assumes the scrapers are written clearly and efficiently to avoid programming errors.
Out of these two, my two favorites (aside from simply programming a web crawler of your own) would I have to be Parsehub and Import.io. Import.io for its wide array of features while maintaining its simplicity when simplicity is all you need.
Selenium will be discussed further later, as it’s a relatively unique tool for web scraping that can be taken advantage of through means other than python.
12. ZenRows
Best web scraping API
ZenRows is the most reliable solution for developers to extract data from websites, saving roadblocks, uncertainty and infrastructure costs.
This toolkit provides you with a premium proxy rotator, headless browsing features, advanced anti-bot bypass and other capabilities that any project at scale will require.
ZenRows seamlessly integrates with Python, PHP, Ruby on Rails and any other programming language. Also, it has world-class support powered by its own developers.
FAQs
what are the pros and cons of using open-source web scraping tools
Open-source web scraping tools have their own set of pros and cons. The main advantage of using open-source tools is that they are free to use and can be customized according to the user’s needs. They also have a large community of developers who contribute to their development and provide support. However, open-source tools may not have the same level of support and documentation as commercial tools. They may also have limited features and may not be suitable for complex web scraping tasks. Additionally, open-source tools may not be as user-friendly as commercial tools, requiring more technical knowledge to use effectively. Overall, the choice of whether to use open-source or commercial web scraping tools depends on the specific needs and resources of the user.
what are the most popular open-source web scraping tools
Some of the most popular open-source web scraping tools include Scrapy, Heritrix, Web-Harvest, MechanicalSoup, Apify SDK, Apache Nutch, Jaunt, Node, and Octoparse. These tools offer various features such as ease of use, support for multiple programming languages, and the ability to extract data from complex websites. Scrapy is one of the most popular open-source web scrapers, while Octoparse is a free and powerful web scraper with comprehensive features. However, the choice of the best tool depends on the specific needs of the user, such as the type of data to be extracted, the complexity of the website, and the budget.
what are the best web scraping tools for extracting data from dynamic websites
Python and Selenium are popular tools for web scraping dynamic websites. Python libraries like BeautifulSoup and Scrapy can be used to parse HTML and extract data from dynamic websites. Selenium is a browser automation tool that can simulate user interactions with a website, allowing for the scraping of dynamic content. Other tools like Octoparse and Apify also offer features for scraping dynamic websites. Octoparse simulates the human scraping process, making the entire scraping process easy and efficient. The choice of the best tool depends on the specific needs of the user, such as the complexity of the website, the type of data to be extracted, and the budget.
what are the advantages of using Python for web scraping
Python is a popular language for web scraping due to its simplicity, readability, and ease of use. Python has a large number of libraries and frameworks that make web scraping easier, such as BeautifulSoup, Scrapy, and Selenium. These libraries provide features like HTML parsing, browser automation, and data extraction. Python’s dynamic typing and advanced built-in functions also make it easier to write complex commands in fewer lines of code, making web scraping more efficient and less time-consuming. Additionally, Python is an ideal language for automation, making it well-suited for web scraping tasks that require navigating to a website, logging in, and extracting data. Overall, Python’s simplicity, readability, and automation capabilities make it a popular choice for web scraping.
what are the most popular Python libraries for web scraping
Some of the most popular Python libraries for web scraping include Beautiful Soup, Requests, Scrapy, Selenium, lxml, and Playwright. Beautiful Soup is a popular library used to extract data from HTML and XML documents, while Requests is used for making HTTP requests and handling responses. Scrapy is a powerful Python framework used for crawling and extracting data from websites, while Selenium is a browser automation tool used for scraping dynamic websites. Lxml is a fast and feature-rich library for parsing XML and HTML documents, while Playwright is a relatively new library that provides a high-level API for browser automation. The choice of the best library depends on the specific needs of the user, such as the complexity of the website, the type of data to be extracted, and the budget.
Overall, despite the two aforementioned programs coming out of my favorites, I still lean towards the assurance of knowing a script will run. Certainly, in many circumstances, proxy services will make life much, much, easier, but other times they can cause headaches in themselves.
