Are you plan to scrape URLs using the ScrapeBox from search engines? To avoid the IP blocked, Nowadays the rotating proxies are one of the best solutions to bypass IP blacklist.

Do you want to use this type of proxies for scraping? Of course! Now more and more guys use rotating proxies for scrapeBox. To let you know more detail about that, I would like to let you know how to use scrapebox with backconnect proxies, I will use the smartproxy as a sample, It’s one of the cheap but effective backconnect proxy network providers.
Table of Contents
A brief introduction to ScrapeBox

Screen scraping or web scraping is how you get data from web sites. ScrapeBox is a very useful tool if you want to find useful information for SEO. For example, you can scrape all URLs for rent ads on a site to find the best deals. If the site is large, you can’t do this manually.
ScrapeBox is the best answer for people who don’t have time to write complex scripts for scraping. It has many good settings, and it is a single-payment program, so you pay once and that’s it – no monthly payments.
Why need Proxies when using ScrapeBox?
ScrapeBox must use proxies, and it has its own public proxy harvester, but it takes time to work and can bring up dead proxies. You can also import your own proxy list to ScrapeBox if you buy dedicated IPs.
But today we want to find out if ScrapeBox works with a backconnect proxy network like Smartproxy.
Can you use a rotating proxy from Smartproxy to scrape with it?
Smartproxy says it is fully compatible with Scrapebox, so we go to set up proxies, first. It uses backconnect proxies for the network, so we can’t check proxies in ScrapeBox.
Note: Though You can use Scrapebox’s proxy Harvester to get the free public proxies, It’s really inefficient!
How to set up Scrapebox with Smartproxy
Proxy setup is pretty simple, and here is what we did:
-
Run ScrapeBox.
-
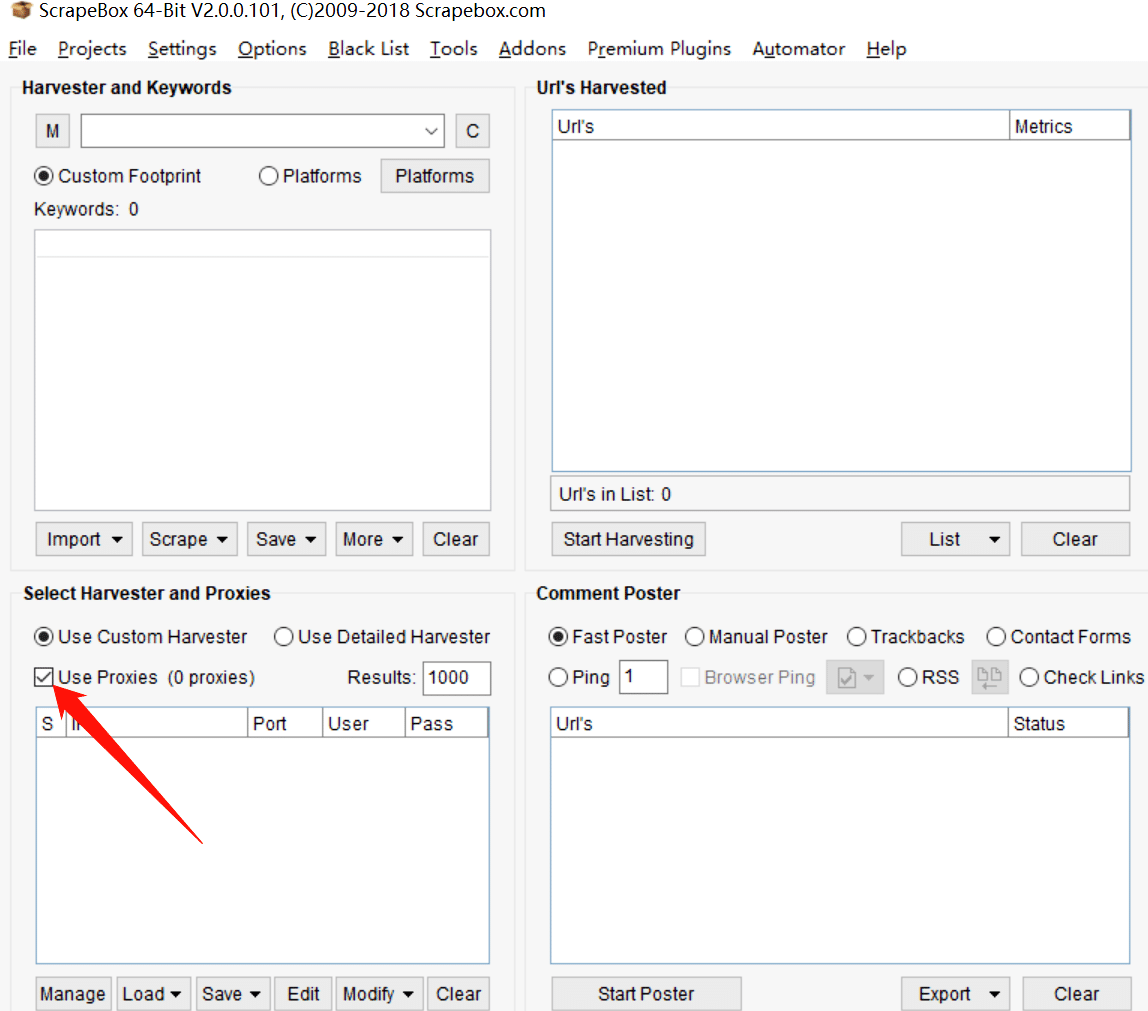
Then, Find out “Use Proxies” in “Select Harvester and Proxies”, then check it.
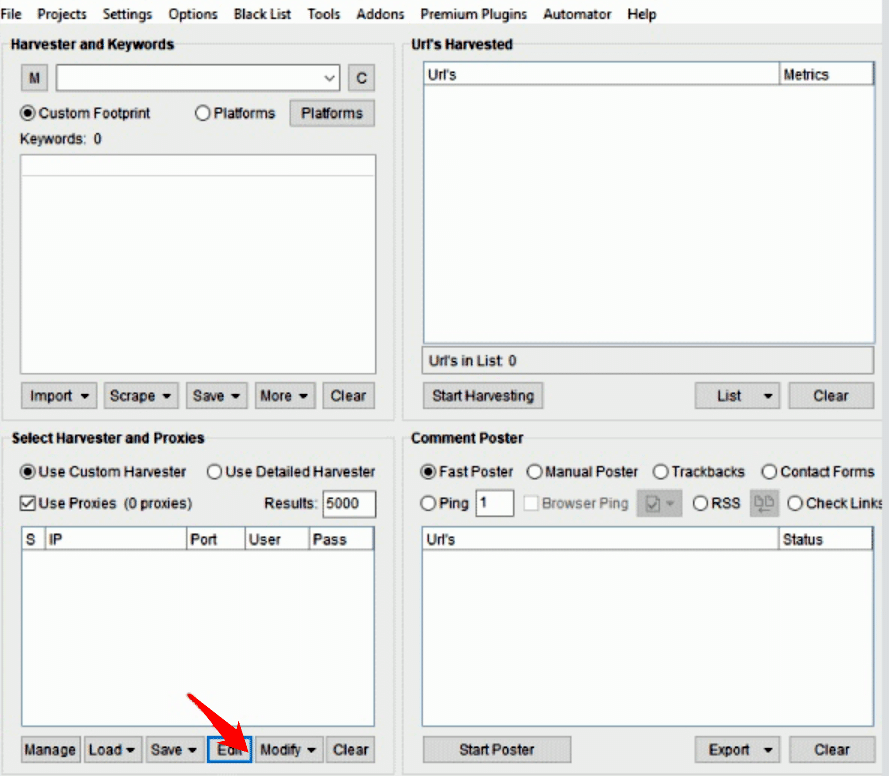
- Click Edit in the same menu to set up proxies.
-
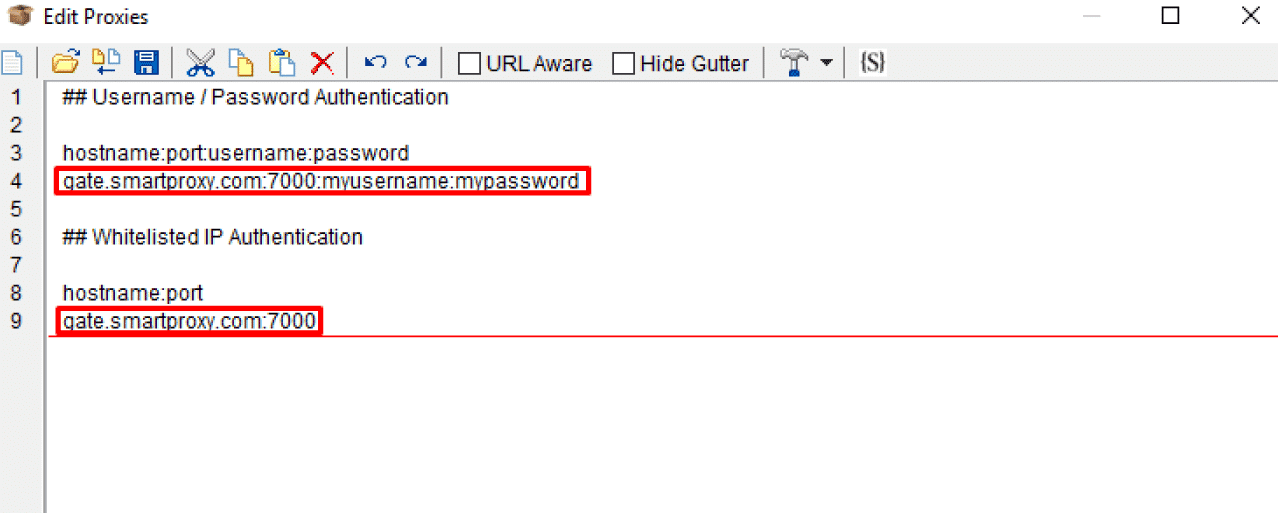
Smartproxy authenticates with user:pass or whitelist IP, so we enter authentication information from our user panel.
Both “username:password” and “IP authentication” method are added! If you still not know how to use their residential proxies, You can read our detailed guide to use smartproxy.
-
Save proxy settings. They show up in the Select Harvester and Proxies settings.
-
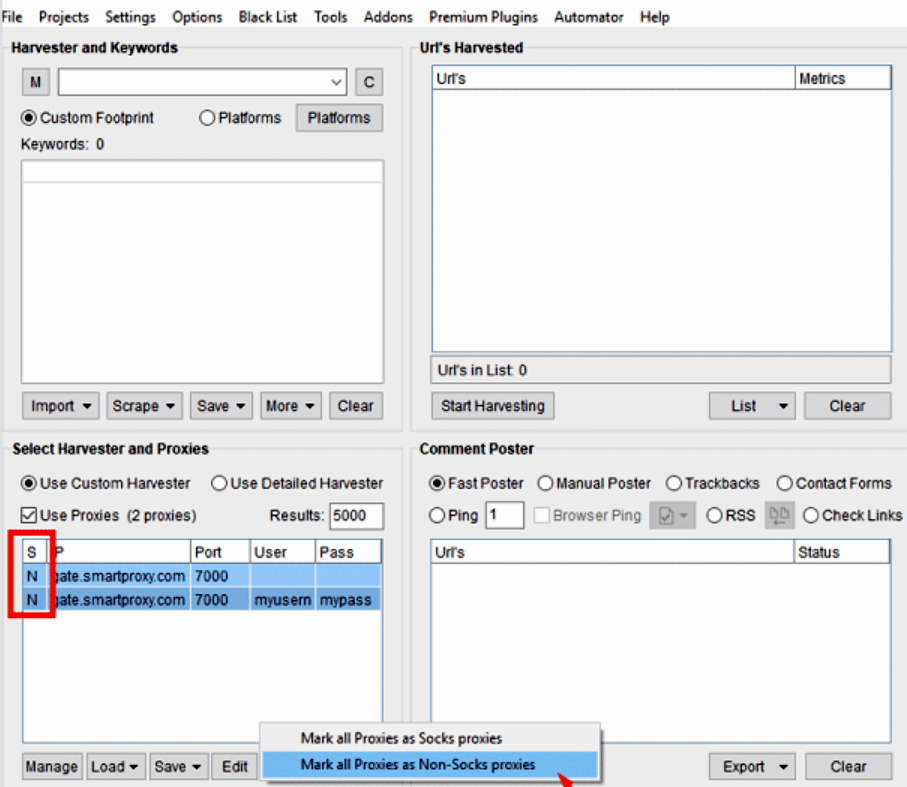
Select the proxies we have entered and click Modify.
-
Select “Mark all Proxies as Non-Socks proxies”.
The letter “N” (None) appears for each proxy in the “S”(Socks) column, You must do like that, For their proxies only support HTTP(S) protocol! For ScrapeBox, the HTTP proxies are enough to Scrape the URLs.
-
Configure the rest of your ScrapeBox settings and run a test: check if the Harvester Status shows Proxies Enabled. If it does, we are ready to run the test.
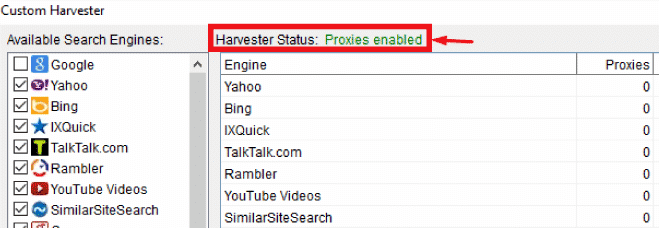
Note: Do not check “proxy status”!
The ScrapeBox’s proxy checker is only supported static IP proxies, Those type of rotating proxies also name as the backconnect proxies are do not support to test, the smartproxy is just one of the proxy provider offer the rotating backconnect proxies.

Smartproxy’s backconnect proxy network rotates IP for each connection, so you will always have a live proxy. ScrapeBox check is set for static proxy lists that can have dead proxies. Smartproxy checks their proxies all the time, so you don’t need to be checking proxies in ScrapeBox.

Once you set up proxies on ScrapeBox, you can start scraping your target. We will do a keyword scrape for a test and use the free Search Engine Harvester that comes with ScrapeBox.
How to scrape keywords with Scrapebox and Smartproxy
This simple test will show if Smartproxy works with ScrapeBox. We choose the keyword ‘Pewdiepie’ and ‘Pewds’. Just add them to the harvester.
We can enter many more keywords, but it does nothing for the test, so we just add two. If this works well, we will have hundreds or thousands of related URLs and keywords to use for SEO analysis.
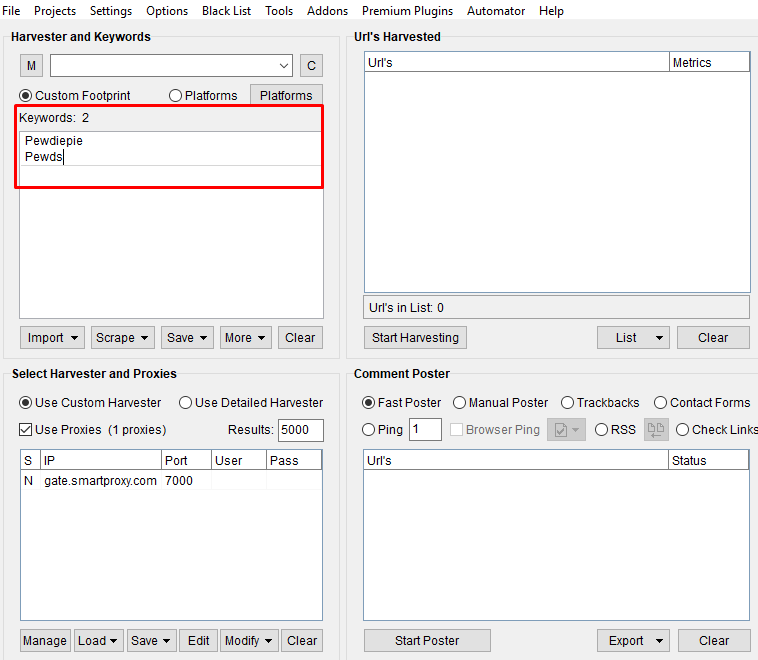 Once we upload all keywords, we click Start Harvesting and then select search engines we want to scrape. Again, it makes no difference how many keywords we add now because if proxies work, they will work for any number of keywords.
Once we upload all keywords, we click Start Harvesting and then select search engines we want to scrape. Again, it makes no difference how many keywords we add now because if proxies work, they will work for any number of keywords.
 We picked six search engines for two keywords: Google, Yahoo Search, Bing, and YouTube, including less popular engines like Search.com and Ecosia.org.
We picked six search engines for two keywords: Google, Yahoo Search, Bing, and YouTube, including less popular engines like Search.com and Ecosia.org.
Before we see if Smartproxy works with all of them on ScrapeBox (Read more test to smartproxy from our review page), we make sure that the Harvester Status says ‘Proxies Enabled’ and only then click Start.
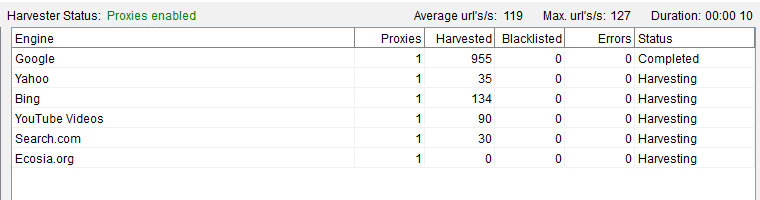
 As you can see in the screenshot below, it takes around 10 seconds to scrape almost 1,000 URLs from Google, with average 119 URLs per second.
As you can see in the screenshot below, it takes around 10 seconds to scrape almost 1,000 URLs from Google, with average 119 URLs per second.
Nice speed! The end result is even better, because we get three times more total results than from Google alone.
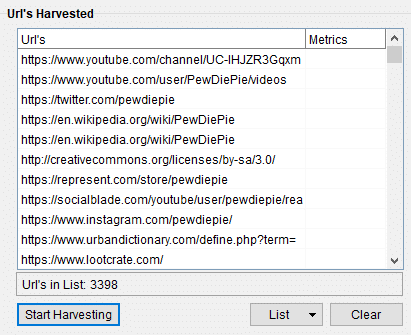
See below that ScrapeBox with Smartproxy scraped a total for over 3,000 keywords for ‘pewdiepie’ and ‘Pewds’:
 We also checked our URL list, and it shows that this scrape resulted in 3,398 URLs. Nice. We can now move on to export this list and use it for other scrapes, research, etc.
We also checked our URL list, and it shows that this scrape resulted in 3,398 URLs. Nice. We can now move on to export this list and use it for other scrapes, research, etc.
Conclusion
As you can see, ScrapeBox works good with Smartproxy, as we got our results with very good speed and without blocks. The backconnect rotating proxies work well with ScrapeBox because you get a new IP address for every new connection. It is a lot less work to use Smartproxy for ScrapeBox than to use the proxy harvester because it often brings up dead proxies.
It’s also nice that Smartproxy lets you use all proxies in the pool (they say they have over 10 million IPs) because of it prices for the traffic use. This scrape, for example, used only under 10 MB.
I would like to hear your feedback about their proxies also, easily leave a comment below!
