Are you scraping E-commerce sites? Read our full guide to learning the best proxies for Scraping E-Commerce websites!

Table of Contents
- Why scraping E-commerce is so popular?
- Why do you got blocked when scraping E-commerce site?
- How do you avoid these blocking techniques?
- Where can I get a large number of IPs?
- Residential Proxy Network is the best solution!
- Bright Data – The World largest residential proxy network
- IPRoyal – Non-expiring rotating residential proxy traffic
- Proxy-Seller – Affordable alternative to Bright Data
- SimplyNode – Cheap price and no monthly commitment
- Nimbleway – Best for Enterprise Customers
- NetNut – High-Speed Auto-Rotating Residential Proxies
Why scraping E-commerce is so popular?
Online E-commerce is a competitive industry with prices changing drastically from different sites to countries.
E-Commerce scraping has emerged as a crucial need for the visibility of insights that other tools and softwares cannot provide.
This helps online retailers understand where their customers are coming from and assists with their marketing and sales.
 For example, to observe the preferences of the customers and their behaviors with various purchases, E-Commerce scraping brings up the perfect solution which requires manufacturing targeted products that are directed towards the demands of their consumers.
For example, to observe the preferences of the customers and their behaviors with various purchases, E-Commerce scraping brings up the perfect solution which requires manufacturing targeted products that are directed towards the demands of their consumers.
That is the reason why E-Commerce Scraping like Amazon Scraping is relatively popular these days.
Why do you got blocked when scraping E-commerce site?
Yes, E-Commerce Scraping might seem the best idea for you, but let me make it clear to you that it is not a piece of cake.
I would like to use Amazon as the sample! Amazon is one of the most popular websites for E-Commerce.
-
IP address
Scraping Amazon is not easy because if they observe even a slight behavior of a fishy IP address or any sort of Bot actions, They will immediately ban the fishy IP address and you will not be able to access Amazon with the same IP address anymore.
There are two reasons as to why Amazon will be banning your IP address from their website.
First of all, If you fail to limit the number of requests that you make in a given period of time, Amazon will see this unusually fast requests per minute and will consider your IP address as bot activity. No website allows the usage of bots on their website. Hence, they will blacklist your IP address after which you will not be able to access their website using the same IP address
Secondly, If you make too many requests in a short period of time, Amazon will be tempted to think that you might be implementing a DDoS attack on the website and they will blacklist your IP address as soon as possible to prevent the DDoS attack. These are the two reasons as to why your IP might get blacklisted from Amazon.
Related: How to scrape a website without getting misled (cloaked)
-
Cookies
When accessing your target website, the website saves cookies on your browser.
Cookies allow you to add items to your shopping cart and browse through their offerings while still showing you the same shopping cart when you are ready to check-out.
-
Request-headers & user-agent
The website is also paying attention to the request-headers and user-agent.
The user-agent is the device you are using and the operating system you are on. This information is collected to display content in the right format and in the right language.
The most important thing that you have to realize is that whatever it is that you’re doing on the website, The website is keeping an eye on your movements.
-
Blocking techniques
That includes the number of requests that you are sending per minute. Moreover, they also watch the number of requests that are being sent by a specific IP address and will blacklist any IP address from their website if the IP address is sending too many requests.
A Crawler is a special piece of software that can make multiple requests in a matter of seconds, unlike a human. It is capable of making requests at a tremendous speed in a short period of time.
With the collection of all this target specific data, retailers are able to see if their competition is entering their site.
Using a competing companies IP address, too many requests per minute, a lack of cookies and an incorrect user-agent are all ways to trigger a website to implement blocking techniques.
Blocking techniques include
- Skewing the data – to show much higher prices when a site is being accessed by competition.

Why is Residential IP Proxy? Read more: Residential IP Proxy Vs. Datacenter IP Proxy.
- Flagging or blocking access altogether – Getting an IP blacklisted is common when you are using a common Datacenter IP address or a non-rotating proxy.
- Presenting Captcha – The website will start to pop up some Captcha which asks to re-write the given text on the screen to check whether the user is a human or a bot. This is one of the most common blocking techniques of a website.
How do you avoid these blocking techniques?
First, you need to be scraping using geo-targeted IPs, for the country or city you require to ensure the relevancy of pricing data.
Collecting pricing data from Europe with prices in Euros is not relevant if your operations are based in the United States and products sold in dollars.
Next, you need to be using many different IPs and this is to avoid being blocked based on your bot or crawlers actions. By rotating the IP after several requests you can camouflage your bot’s actions to seem like a real-user and continue successful scraping.
Along with a large number of IPs, your bot needs to stay anonymous.
Anonymity will allow you to ensure the pricing data you are collecting is accurate and not skewed by your competitors.
Where can I get a large number of IPs?
Residential Proxy Network is the best solution!
If you want to be scraping E-Commerce websites, You need a large number of IP addresses that you can choose to switch between so you can minimize the chances of your IP address getting banned from the website.
This purpose is excellently served by A residential proxy network. A residential proxy network provides you with a pool of IP addresses and constantly replaces your IP address with that from the IP pool. In this way, Your IP address is never the same and Websites have a hard time checking whether you’re using a bot or not.

Bright Data(formerly Luminati) is a great choice for such a proxy network as they provide better pricing for all your scraping needs. This is due to the fact they provide a free Proxy Manager that contains a preset configuration called, ‘online shopping’. This preset automatically applies the optimal proxy configuration for content curation from product pages.

The automated setup includes:
- DNS resolve remotely by the peer
- Changing the user-agent for each request
- Applies a post-processing rule example
- Enables SSL to see request log details
Read more about our ultimate guide to Luminati’s residential proxy network.
The ‘online shopping’ preset gathers the product pages title, price, and description list which took out all of the grunt work.
IPRoyal might not offer as big of an IP address pool as others on the list, but they offer a unique feature beneficial for data scraping. Rotating residential proxies are most commonly used for web scraping as they regularly switch IP addresses to avoid detention and maintain excellent success rates. Unlike most providers, IPRoyal does not set the traffic expiration date, so you can use your rotating residential proxies whenever you need.
This is an excellent feature for those looking to develop their own scraping setups. IPRoyal’s proxies will be ready whenever you are ready to launch your operation. Simultaneously, the more traffic you order, the lower the cost, going a few times below market average for large business operations. Lastly, there’s a pay-as-you-go payment model, so you never have to spend more than you use.
Proxy-selling can be used for web scraping on popular e-commerce websites, such as Amazon, Walmart, and eBay. One significant advantage of using a proxy-seller for E-commerce is its affordability. If you’re on a tight budget, a proxy-seller is a cost-effective alternative to Bright Data that can be quite expensive.
Proxy-seller services typically offer various payment options, including pay-per-use, monthly subscriptions, and yearly plans, making it easier for you to choose a payment option that suits your budget and needs.
SimplyNode’s residential proxies are ideal for scraping e-commerce platforms like Amazon and eBay due to their extensive network of over 50 million ethically-sourced IPs in 180+ countries. This vast IP pool allows for precise targeting at country and city levels, essential for localized data collection. The ability to rotate and maintain sticky sessions helps avoid detection and blocking.
SimplyNode’s transparent and flexible pricing, starting at $6 per GB with no monthly commitment, makes high-quality proxies accessible for businesses of all sizes. This cost-effectiveness, combined with broad geographical coverage, makes SimplyNode perfect for comprehensive market research and competitive analysis on major e-commerce sites.
The Nimble residential proxies are one of the best proxies for e-commerce tasks. While reviewing their proxies, we tested them on popular e-commerce platforms such as Amazon, Adidas, Nike, eBay, and even Booking It has proven to have one of the strongest anti-spam systems in the market and the result was as great as any of they didn’t detect it. One good thing about this provider is that it has all it takes to be used as an e-commerce proxy.
If what you need is to manage your single or multiple accounts on e-commerce sites, you can use its sticky session proxies for an extended period of time. For scraping e-commerce platforms, it high rotating proxies have been set up to do the job and avoid exceeding request limits that will lead to you getting blocked.
The service has millions of IP addresses in its pool sourced from over 190 countries across the globe. It does support geo-targeting, making it possible for you to scrape geo-targeted content from e-commerce platforms.
In terms of pricing, Nimbleway is expensive for small proxy users. Its minimum monetary commitment is $600 for 75GB. While the price per GB is $8 and cost-effective for those who can afford this, small users can’t. For enterprise customers, there is a 22GB free trial provided after KYC.

NetNut provides Reliable Static Residential and High-Speed Auto-Rotating Residential Proxies that are highly suitable for crawling and scraping various e-commerce platforms. However, if you’re navigating the realm of general e-commerce, their rotating proxies emerge as the ideal choice. These proxies are exceptionally difficult to detect by switching IPs at the right time, making them a perfect solution for tackling data-rich e-commerce sites like Amazon, eBay, and Walmart.
NetNut’s auto-rotating proxy network stands out because it operates through over 52M+ real end-user devices worldwide. Such a massive pool allows you to access any website with the highest level of anonymity and security. The days of dealing with CAPTCHAs and IP bans are over, as NetNut’s rotating residential proxy, which does not send requests through U.S peer proxies, guarantees a seamless and untraceable data collection process.
Because of its vast pool of real residential IPs distributed globally, NetNut gives you a significant advantage in accessing e-commerce sites from any corner of the world. The country and city-level targeting feature empowers you to execute precise geo-targeted campaigns, conduct market research, and safeguard regional brand interests like never before.
With NetNut’s customizable rotation options, you can fine-tune your data extraction processes, effectively manage ad campaigns, and enhance privacy measures as needed. This tailored approach particularly benefits B2B, enterprises, and businesses within the technology, information, internet, IT services, and consulting industries.
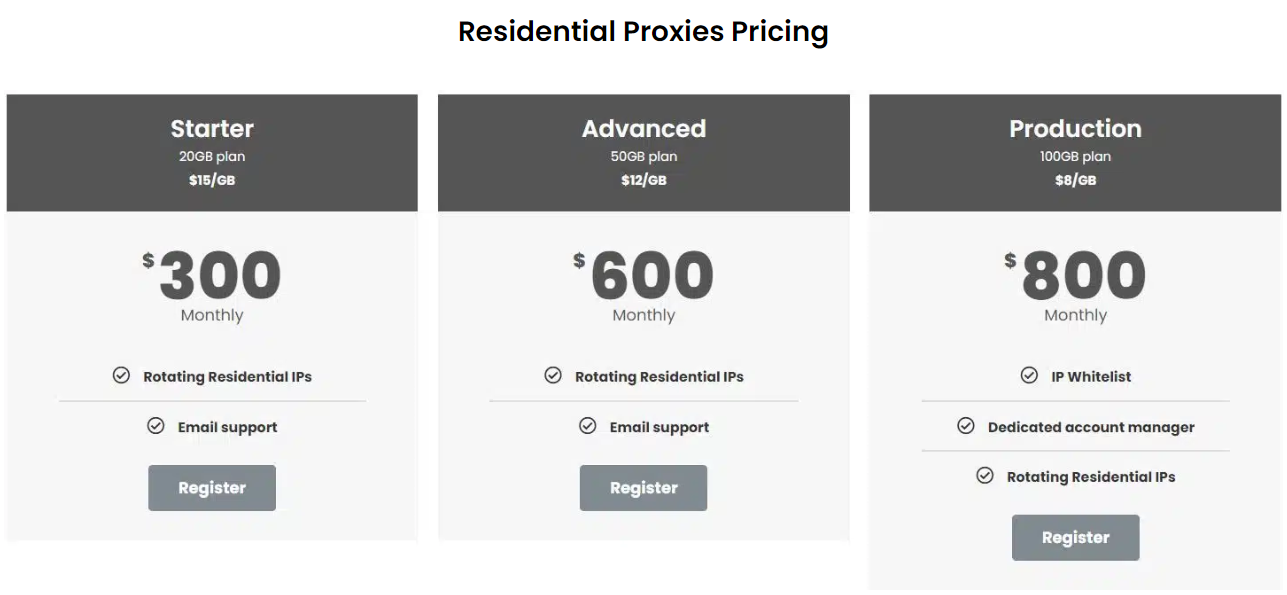
Starting at an affordable price of $300 per month for a big chunk of 20GB of data, NetNut’s Residential Proxies is a pocket-friendly solution to help you do more web scraping and data extraction on e-commerce platforms.
You can get even bigger e-commerce bandwidth with the Advanced Plan. Priced at $600, it grants a juicy bandwidth of 50GB for one month, enabling you to delve deeper into data and engagement strategies with your e-store audience. If you want to see just how well they work, NetNut lets you try them out at no cost for 7-days. This way, you can experience firsthand how these proxies can help you elevate your data-mining game to greater heights.
Whether you are coding your bot or crawler yourself or using an all-in-one solution like Luminati, the most important thing is using a high-quality proxy network.
Note: Now luminati.io offer both Luminati Rotating Residential Proxies and Static residential Proxies!For data scraping you have to use their Residential Rotating Proxies!
This network should have geo-targeted, rotating residential IPs.
By utilizing a residential proxy network with the right proxy manipulations you can make this environment transparent again and truly gather the most accurate and competitive pricing.
