Have you tried to scrape a website and things did not go as planned? Scraping is not as simple and easy as most people think. Today’s guide will outline several important tips and tricks to improve your scraping game.
In modern times we live in data plays a very crucial part of our lives, both on a personal and professional level. As we spend more and more time online, we create more data, and the numbers will only grow exponentially. To put that into perspective, here are a few data-based facts.
It is estimated that a single user creates around 1.7 megabytes of data every second, and daily, all of the people that have access to the internet, which is more than half of the people on the planet, are generating around 2.5 quintillion bytes of data daily. It is estimated that this year there will be over 40 zettabytes of data, which is 40 trillion gigabytes (with twelve zeros).

As you can see, there is a lot of data, but not all of it is useless junk we post online. A lot of the data can be used for various purposes, which is why web scraping is so popular — web scraping is a process of gathering data from a source that you can later use. For example, marketing companies can gather data and analyze it to help them make certain predictions and create better campaigns.
In the olden days, when there was much fewer data online, scraping was done manually. People would copy and paste the information they need, and it was something that did not take too much time to do. Today it is a different story. Grabbing data by hand can take years to complete, which is why we have automated software for that called scraper. The scraper goes through the source and collects the data that you tell it to.
Even though scraping with software seems simple and easy, there are some aspects that you need to be careful about, and this article will help you with that. We are going to cover several tips and tricks to improve your scraping game and avoid common mistakes.
Use the right scraper
The need for more and more data means that more and more tools are becoming available online that can scrape data. Today there are hundreds if not thousands of data scrapers, each one having its own unique set of features and possibilities.
Most people think that you should get the scraper first and then start analyzing the data. That can be a big mistake. Since most of the scrapers are unique, and some can do what others lack, you should first analyze the data and see what you need to scrape. Once you have that figured out, you can start researching for the scrawler that best suites your or your company’s needs.
The two main obstacles that a lot of people face are captchas or logins, and both can be a headache.
Publicly available information is always easy to get, but if you are scraping, the server might notice a lot of requests and can start asking you to solve captchas. In some cases, you may start seeing them after a few tries, but in other cases, you can start seeing them since the start. If you need to grab data and you know that there will be captchas, you do not need to worry; there are a lot of scrapers that can solve them for you.
Logins are another big problem in the world of scraping.
Data that is not publicly available means that you will first need to log in before you can access it. Just as with the captchas, there are a lot of scrapers where you can set them up to log in to a website and start pulling data. Every time you log in, you receive cookies that show the server that you are already logged in. the scraper will log in for the first time and keep the cookies even after the session is over so that when it goes back to scrape another piece of data, it will not have to log in again.
An additional step that is also optional is to set up multiple accounts. If the server gets suspicions of “your” actions, it may block the account, and your scraping will be over. To prevent this, see if you can create multiple accounts and have them all run simultaneously. That way, even if one gets banned, the others can continue to work.
Price also plays a crucial role in this. Some might think that the most expensive one would be best, but that is not always the case. You might find yourself in a situation where some expensive service will cost you hundreds of dollars, but some free pieces of software would suit your needs better.
Ideally, you would want to test out a few shortlisted services of applications and then decide which one to go for. It is a process that takes a bit more time, but at the end of the day, it will be worth it.
Headers
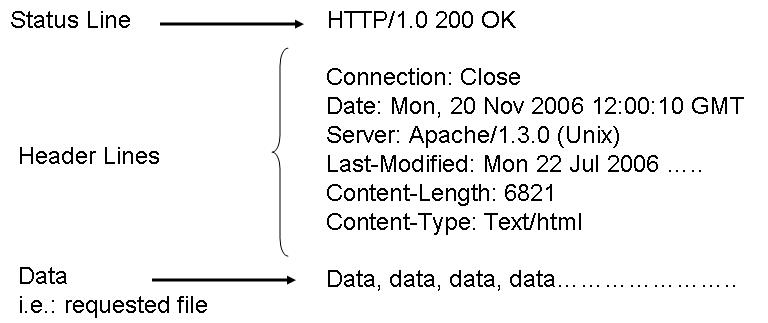
On the internet, headers are bits of code that are sent out after the request to the website. Within that code is store the information required by the website or service to provide you with what you want. In simpler terms, every time you want to open Facebook in your browser, a request is first sent out asking the server to load the page, and right after that, the header is sent containing additional information, like browser, version, operating system, etc.
In the world of scraping, it is a different story. The simplest and most common way to scrape is with cURL, and a lot of people use it. The problem with it is that if you try to scrape off Facebook without making any changes to the parameters, you will be left empty-handed. The reason for that is that Facebook’s servers will see the header and will know that your intent is to scrape, and they do not want that.
There are two solutions to this problem. The first one is to mimic headers from regular browsers, or you can go headless (no, this does not mean chopping heads off).
A lot of scrapers will offer you the ability to make changes to the scraping parameters to get the results that you want, and headers are one of them. In the previous example with cURL, you can use a header from a Chrome or Firefox browser, and Facebook will have no problem with you accessing it, even if it is for scraping.
Copying the header of a regular browser is easy, but the complication is that to be effective, you would need to set up multiple different headers if you do not want to raise any suspicions.
The second choice is to go headless. That is the situation where your requests are sent, but a header is not. Scraping headless is a slightly older technique, and a lot of modern sites have taken precautions to fight it, so try not to use it unless it is absolutely necessary or if the first solution failed.
Proxies
Even though it is not the first tip in the article, it is probably the most important one. Over the years, proxies have been getting more and more attention and more and more applications. Their main application is to change your IP address and make it look like you are from somewhere else.
So, how will proxies help you when scraping?
1. Send multiple requests from a different IP address
When you are scraping data from a website, the process occurs multiple times in a second. The scraper makes a request to the website, grabs the data, and goes back to store the data in a spreadsheet. Some scrapers are capable of making hundreds of these trips in less than a second.
The problem is that a lot of modern websites can recognize these very easily because, let us face it, no person works that fast. This is where proxies come into play. If the server sees multiple requests in one second, but if all of them are from different IP addresses, then there is a slim chance that they will get banned.
2. Get Geolocated IP address
The second way that a proxy can help you is with geo-location. For example, if you live somewhere in Europe and you want to scrape a US-based website, you may come in a situation where the website will not be available to you because your IP address is not US-based. As we mentioned previously, proxies can change the IP address that the server sees, which means that if you have US proxies, you can scrape a website with no limitations.
There are two most common types of proxies out there are data center and residential proxies. The cheaper option is the data center proxies because companies are buying them in bulk and can sell them to you in the same way. The downside is that these are almost always “marked” as proxies, and some servers may already have them blacklisted.
The safer approach is with residential proxies. These proxies are essentially people’s home IP addresses that you can use, and this is the reason why they are the safer approach. You get to use those people’s home IP addresses that have a very low chance of being on a blacklist. The downside to the residential proxies is that they are slightly more expensive.
The flip side to all of this is that there are tons of proxy providers that sell both data center and residential proxies. Among the most popular ones are Luminati, Smartproxy, Shifter, and many more.
Humanlike Scraping
This will be a tip based on several smaller tips.
The reason that most scrapers are having a difficult time grabbing data is that in their core, they execute instructions based on your commands. You ask it to go to a website and grab as much data as possible in the shortest time. That is why most servers are equipped to fight them. The last tip for you today is to try to make your scraper more humanlike, but what does that mean?
Each scraper takes milliseconds to go toa website and grab data. So, if a server sees that someone is making a request every, for example, 20 milliseconds, it will know that it is dealing with a scraper. To prevent complications, try to set up your scraper with certain delays. For example, set it up to wait a random amount of time after each data grab. In return, the scraper will sometimes way one millisecond, or it can wait 78 milliseconds, depending on your settings, and that might be the thing that will keep your scraper working without getting banned.

Another more humanlike behavior of a scraper is the headers. We already discussed them previously, but this is a tip on how to make them human-like. Getting a header from a real browser is not the problem, but if you enter your personal information in it, then there is a slimmer chance of the sever thinking it is a scraper. Even if you are setting up multiple headers, still try to use authentic names and email addresses for them.
The second tip is up to you, but it is something that you can consider. In the introduction, we mentioned that there is a plethora of web scraper on the internet, and a lot of them are varying in terms of price and features. Regardless of that, you can still find some scrapers that have similar features and similar pricing, so the tip here is to try to scrape with two different scrapers.
The reason for that is that even though two or more scraper might be similar in features, their performance may vary, so there is a chance that your scraping might be more effective. Most people do not use this technique, but it is something that you can consider.
Scraping a lot of data can be a problem, especially if you know that the scraper you are using will not be able to grab everything in a few hours. If you are scraping millions of records from a website, it is recommended to divide the data into smaller chunks. But why would you do that?
The servers, of course. Grabbing millions of records means that the scraper might need to run for several days, which in return may overload the server, depending on how fast the scraper is working. An overloaded server usually performs worse than a non-overloaded, and often the sysadmin will need to investigate and may either put the server offline till the “issue” is resolved or might figure out that someone is scraping. To avoid this, break up the data in smaller chunks and scrape a few hours at a time with breaks in-between
Conclusion
People that are constantly scraping will say that these are not the only tips for scraping, and they are correct. These tips are aimed towards beginners that have not scraped all that much in the past and are getting on board with that. Once you get past these, there are numerous more scraping tips and techniques for advanced users.
We hope that these tips will help you get started and overcome some of the most common beginner scraping issues.
