Do you need to scrape search engine results and do not know where to start? In this guide, we will talk about how easy or difficult it is to scrape off some of the most commonly used search engines.

Search engines have been around for quite some time. In the early days of the internet, as we know it today, there was a lot less content and websites – thousands of times less. I in the early 90s, only a handful of websites existed, and most of them contained only text and maybe some images. In 1993 the first search engine Archie was born.

Since those days, a lot of new engines came to be, and they have changed a lot. What was once a simple text searching interface today is some of the most complex pieces of coding out there. To the average user, a search engine is something that provides results based on input parameters, but in reality, it is almost an artificial intelligence capable of providing so much more.
Just like search engines, scraping data is something that has been around for quite some time. Unlike the search engines, scraping has evolved quite a lot since it initially came to be.
In the olden days, people would scrape data off of websites manually by copying and pasting the data. As the amount of data kept increasing the process of scraping, it became more and more complicated, and that resulted in the creation of scrapers.
Since the release of JumpStation back in 1993, web scrapers have increased their numbers greatly. Today there are hundreds of scrapers available online that have a lot more features and are a lot more capable than the ones from over two decades ago.
Combining search engines and scrapers is not something that most people would find common, but it is a lot more common than most people think. So, you might ask: why would someone scrape from a search engine? To grab data, of course.
Scraping a search engine does not mean that you will use software to get everything. Grabbing everything from Google is maybe doable, but might take years to complete. Think of it this way: you can get everything from a dictionary, but doing that takes way too much time, and most of what you grab from there will be useless for what you need.
Instead, when scraping a search engine first, you need to do a search using a keyword and then do the scrape. The reason why this is better is that when you search, the search engine organizes the displayed data in a way that you can use. For example, we searched on Google using the keyword “scraping,” and we got: “About 36,000,000 results (0.46 seconds)”. Just imagine, we have around 36 million results with links, meta descriptions, etc. and it is ours for the taking.
Unlike scraping a website, a search engine might not be as easy as it sounds. Sure, essentially you need a scraper, but there are a few things to keep in mind. As search engines evolved, so did their protection against misuse. A search engine is for finding something, not for grabbing everything you can, but that does not mean that you cannot do it.
What do you need to scrape a search engine?
For a successful scrape, you need two things: scraper and proxies.
Scraper
This is an obvious one, but it has to be mentioned. Be mindful of which scraper you choose because not all of them can scrape from search engines. ScrapeBox, Netpeak Checker, and Scraping Expert are only a handful of scrapers that can grab data out of search engines.
Proxies
Regardless if you are scraping a website or a search engine, proxies are crucial to getting the job done. When scraping, you are making thousands of requests every second, and if you do that from a single IP address, let us say your home IP, then you will get banned long before you manage to get something useful.
Solution – use a proxy.
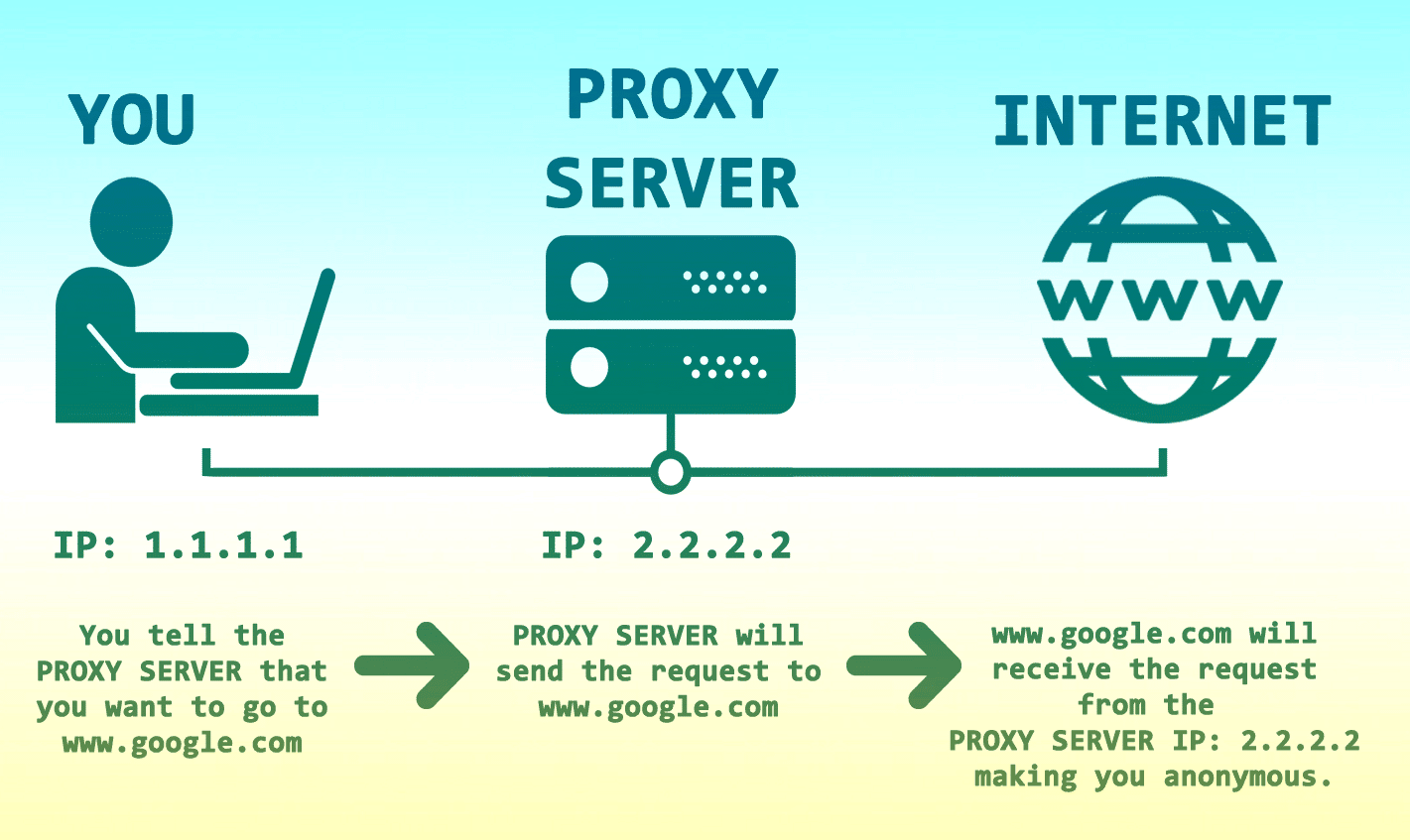
The main advantage of proxies is that your home IP address remains anonymous, but there is another. When you are using proxies, you can make more than one request each time, and you will be getting more data back during each request.
Ideally, you would need to get rotating residential proxies, as they are people’s home IP addresses and are more likely to work. Datacenter proxies are usually already flagged as proxies by most of the servers, so you might be left empty-handed. The downside to residential proxies is that they don’t come cheap. You have tons of choices when it comes to proxy providers. You have Luminati, Smartproxy, Microleaves, StormProxies, and many more.
Precautions
There are two things that you need to be careful: timeout and sessions.
Timeout
Timeout is how long the scraper waits before making a new request. Setting this too low will definitely get you banned because no person can do a search and copy a link in less than a second. In this case, it is recommended to go with a higher number. The negative side is that scraping will take longer, so try to find a middle ground.
Sessions
Sessions are the number of “virtual scrapers” that will be making the requests and grabbing the data. Having more sessions is a good thing because you will be getting more data every second, but having too much can also raise some red flags with the search engine, and things might not work as you initially intended. Try not to go overboard with this.
Our recommendation is to start off slow. Put a high timeout, maybe 20-30 seconds, and start from there. Also, do not go all-in with hundreds of sessions – start with a few and gradually add more sessions and start to lower the timeout. At a certain point, you will reach the limit and will start to get your IP addresses blacklisted, and that is not something you want to do. Many providers rely on those IP addresses and are promising customers that they will work, but if you get a lot of them banned, you might have a lot of explaining to do with the provider.
The best approach is to start slowly and start to increase. It might take more time, but that way, you will have little if any IPs blacklisted and still get the results you need.
What is Best Search Engine to scrape?
All of them and none of them. Search engines have certain measures to keep you from scraping, but some are slightly easier than others. There are a lot of search engines on the internet, so we are only going to cover the most popular ones.
We are starting this with the most popular and the most difficult search engine for scraping. Being the most popular also means that it is the most advanced, so you will face a lot of obstacles when trying to scrape data from there.
Google is very strict when it comes to making requests from it, so often scraping is a hassle. Often even when I am doing a lot of searches for research, I get captchas after around 15-20 searches, depending on how fast I make them. In this case, Google thinks I am a bot and flags my IP address and throws in a captcha every time I do another search.
The same goes for scraping. You will barely do a few pages before Google flags you and put your scraping career on a halt. When doing a manual search, your IP address gets flagged, but you will solve a few captchas, and you will be fine. When scraping, the flagged IP address can get banned or even blacklisted, depending on how persistent the scraper is.
Being older than Google, most people might think that they have higher standards and better protection when it comes to scraping. Well, not exactly.

Yahoo is a scraper that is a bit easier to scrape than Google, but far from the easiest. If you overdo it when scraping from there, you will also get captchas, but unlike Google’s captchas, these are notorious for being problematic. Regular users had tons of problems with them during normal searches, so you can only imagine how problematic it can be when scraping.
If you tune things right, you can scrape quite a lot from yahoo, but it will take you some time to get things right.
We come to the easiest search engine for scraping. Compared to the other two, Microsoft’s Bing is still in its early days of existence, but that is not the case why you can scrape it with ease. The real reason is unknown, and honestly, no one cares. The most probable reason for the lack of protection is that Microsoft wants someone to use it, even for scraping, and we are not complaining.

To show you how easy it is to scrape Bing, here is an example – with very little tinkering in the scraper settings, you can easily get several million results without Bing batting an eye. Google, on the other hand, will kick you out after several hundred.
Bing is heaven for scraping, and a lot of people scrape from it for the same reason, but if you are after good and accurate results, Google is the way to go.
Other Search Engines
Google, Yahoo, and Bing are not the only search engines you can scrape. Technically you can scrape any search engine you can find; the only difference would be the quality of the results and the security measures taken by the developers of the search engines.
In reality, not many people scrape search engines like Yandex, Baidu, DuckDuckGo, or Ask. Users that have scraped them, probably for researching have reported that they are not extremely difficult to be scraped, but also not the easiest. Taking that into consideration, I would put them in the same basket as Yahoo.
Conclusion
Every search engine can be scraped. The difference between them is how easy it will be for you.
While Google may provide and structure the results in the best possible way, Bing will let you scrape all day without asking any questions. Regardless of which you intend to grab data from, make sure to fine-tune your scraper and make micro-modifications to the settings to be able to get the best results in the shortest time. Most of the other search engines are somewhere in-between.
